Xiao Tan: Semantic Segmentation of Weakly Labeled Retinal Images
Posted on Tue 28 March 2023 in theses
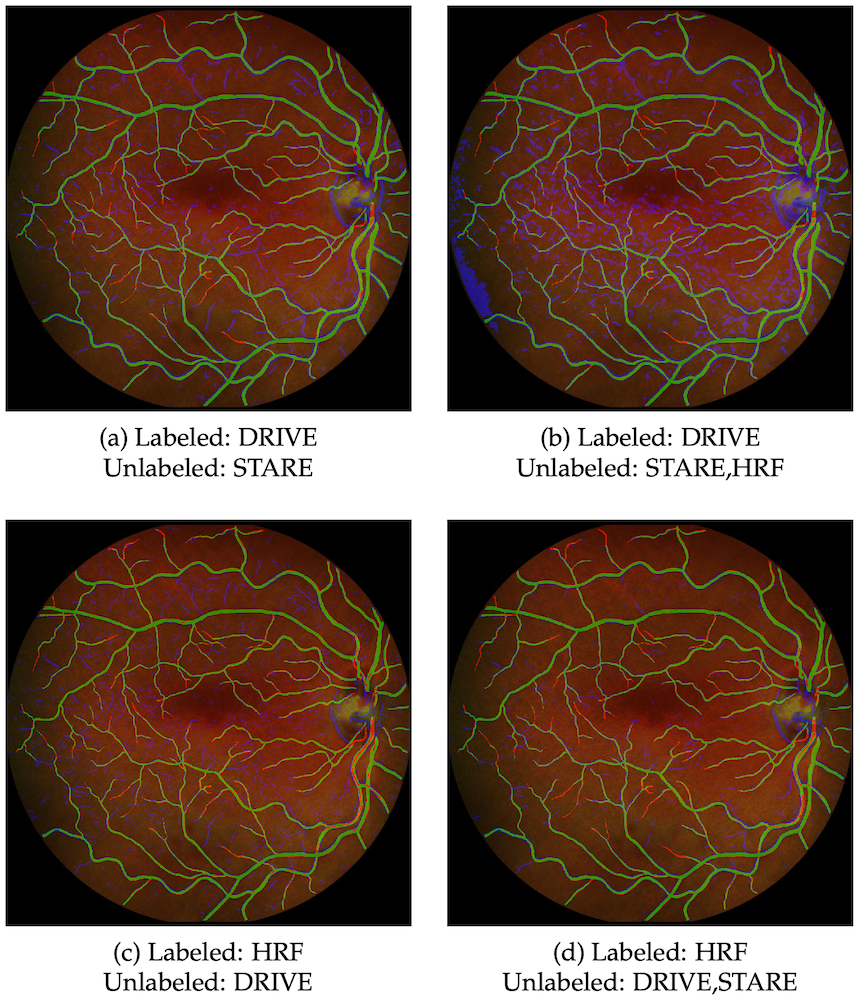
This figure shows different predictions on dataset IOSTAR when increasing the number of unlabeled datasets. Green lines indicate true positives, red lines indicate false negatives, and blue lines indicate false positives. The captions under each image indicate the labeled dataset and the unlabeled datasets used to train the model.
Semantic segmentation is an important task in computer vision. It performs pixel-level labeling with a set of object categories (e.g., human, car, tree, sky) for all image pixels; thus, it is generally a more demanding undertaking than whole-image classification, which predicts a single label for the entire image. Since Machine Learning is proposed, numerous supervised models have achieved very good performance in semantic segmentation tasks with reasonable computation costs. However, the performance of the supervised model is limited by the quality and amount of the labeled datasets, which are scarce and expensive to obtain. This work adapts a popular semi-supervised learning method, namely consistency learning, to the retinal vessel segmentation task. The main idea of this method is to minimize the differences between two predictions generated from two variants, which are produced by applying data augmentations to the same input, meanwhile, to maximize the agreement between the prediction and the ground truth. Because the distribution of pixels belonging to the vessels is sparse, limited data augmentations can be applied to the samples to produce the variants in this task. We figure out the basic data augmentations providing the best performance and test the model on four publicly available datasets. Our results suggest that our model can significantly improve the prediction performance on the labeled/unlabeled dataset pairs which have poor generalization ability in the supervised learning methods. For an unseen dataset, it is important to choose the labeled dataset used in training carefully. When the model is trained with a properly chosen labeled dataset, increasing the number of unlabeled datasets can improve its performance.