Driss Khalil: Multi-task Computer-Aided Segmentation for Eye Fundus Imaging
Posted on Fri 15 July 2022 in theses
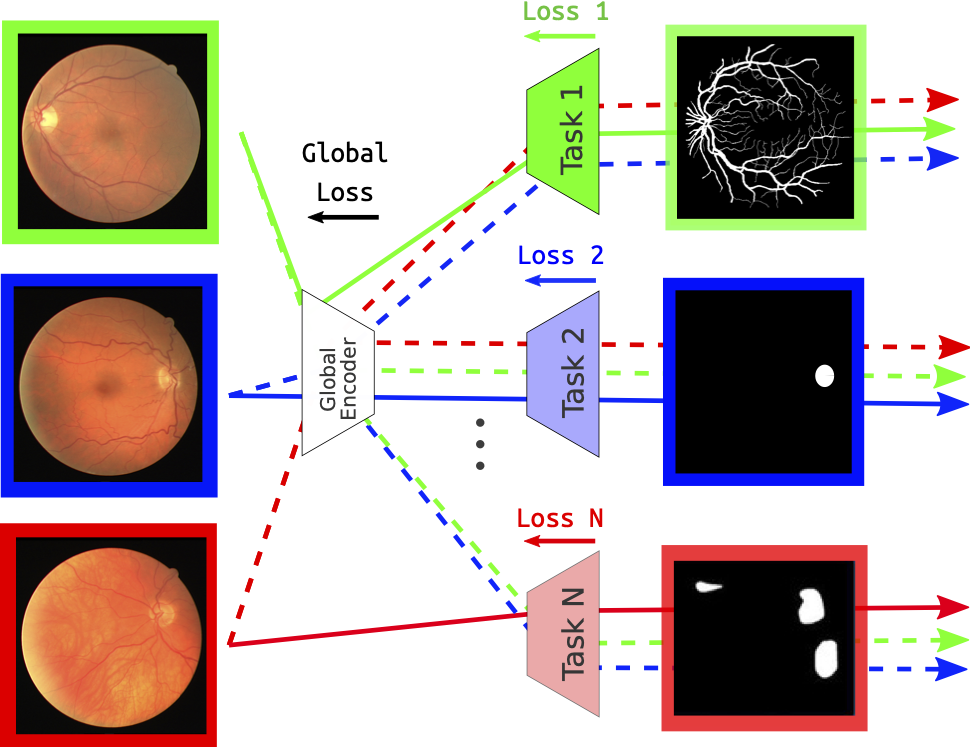
Overview on the multi-task method dealing with segmentation tasks of the eye fundus elements.
The human eye remains one of the essential organs in the human body; it can be affected by several diseases that can cause irreversible blindness. These diseases can appear without any visual symptoms; a late diagnosis would cause the loss of sight and cause blindness. This project's global goal is to detect those diseases using two-dimensional eye fundus images. Nevertheless, in all healthcare-related projects, interpretability is an essential element to care about. Detecting the eye elements is one of the ways to improve the interpretability, as the healthcare specialist will have an overview of how the model did classify the diseases.
In our work, we studied a new multi-task approach that could detect all the eye elements and classify the diseases using one model. As we wanted to explore more views on this approach, we focused in this project on segmenting two essential elements of the eye fundus, the vessels, and the optic disc, as they are the elements that are affected mainly by the diseases.
To address this, we disposed of several public datasets for each task. Firstly, we generated some baseline results using single-task approach models. Secondly, we analyzed the results provided by each model, and we decided to choose U-Net as the model we want to work within our Multi-task learning approach. All the datasets in our work were annotated on one specific task, making us look for a method that can work with disjoint datasets. The chosen method was based on alternating the training between the tasks at each epoch. We generated a ground truth for the non-annotated task using the predictor of the previous epoch. We tested the model on new datasets with different image quality for each experiment, allowing us to test our model's generalization. The chosen experiments were based on evaluating the model's performance using multiple images from different datasets and assessing the effect of having an imbalance of the images between the tasks. The metric used to compare the results was the F1-score.
From the baseline method, we remarked two problems: the enormous noise in the training and validation losses and the non-convergence compared to the single-task approach. Two methods were proposed to face those problems. The first one consisted of using gradient accumulation to update the model's weight once at each epoch. The second method was to generate the ground truth of the non-annotated task using the best epoch predictor.
The results have shown that the gradient accumulation approach decreased the noise from the losses. Still, the method based on the generation of the ground truth from the best epoch failed to help the model converge and caused even a higher loss than the baseline method.